Kernel Hacking - Introduction To The Linux Kernel(1/3)
This guide will walk you through a brief introduction on how to get started with kernel hacking. The guide is split into three parts, each one covering one of the following topic:
- Part one(this one): Introduction to the Linux kernel architecture;
- Part two: Building a device driver from scratch;
- Part three: Introduction to syscalls, how to create a new syscall;
While this guide aims to provide a beginner-friendly resource to get started on kernel hacking, I will take for granted the following knowledge:
- How to program in C;
- How to program in x86 assembly(Intel syntax);
- How does an operating system work;
- How to use a Linux system;
In this first part of the guide, we will introduce some basic theoretical aspects of operating systems in general and of the Linux architecture.
Keep in mind that this guide - and any other available on the net - will not give you the proficiency required to understand the whole Linux source tree. In fact, most Linux developers out there know just a small subset of the entire thing. Even though, this guide will provide you the foundations needed for any field of application.
Setup a Development VM
As any other field of programming, we need to configure a working environment. In order to do that, it is advisable to deploy a development virtual machine where you can download the kernel source tree, a C compiler, a text editor and some other tools. A virtual machine will allow you to easily reboot your machine, create snapshot, analyze kernel panics and so on. You can choose any distro of your choice, in this guide I will use Arch Linux in order to have nothing but the bare minimum. I will not install a GUI, everything you will see here will be done through SSH or via tty. This is the resources I will assign to my VM:
| Resource | Size |
|---|---|
| CPU | 4 cores |
| RAM | 8 GB |
| Disk space | 35 GiB |
| Kernel | 5.15.16-1-lts |
What is a Kernel?
Let us start from the beginning. An operating system is a software that controls the computer hardware and that provides basic functionalities to other programs. One of the essential component of an operating system is the kernel. The kernel is the core of the operating system, that is the subset of an operating system that allows interactions between software and hardware. The kernel is also the portion of the operating system that is loaded by the bootloader at startup and that is in charge of setting up all the rest of the operating system.
In order to manage the underlying hardware, a kernel uses the so-called interrupts. An interrupt is a mechanism used by the hardware to notify the kernel that some event needs immediate attention. Whenever an interrupt occurs, the kernel freezes its current activities, saves its state and then, proceeds to call an appropriate function called Interrupt Service Routine(ISR) to deal with the event. Once the interrupt has finished, unless it indicates a fatal error, the previous activities can be resumed. In order to know which ISR to call, the kernel has a particular data structure called Interrupt Description Table(IDT) where each IRQ(Interrupt Request) is associated with an ISR.
There are some different kernel topologies. A monolithic kernel runs in a single address space all in supervisor mode. A microkernel runs most of its service in userspace. A modular kernel allows loading and unloading kernel modules at runtime.
Linux is a monolithic, modular kernel.
Supervisor Mode vs User Space
In the previous section, we introduce these two terms. Let us give an explanation:
- Supervisor mode(also kernel mode): Portion of the virtual memory designed for the kernel and the device drivers. In this privileged portion of the memory, the software has full control over the computer hardware;
- User spacealso userland): Portion of the virtual memory designed for user applications. Each user space process runs isolated in a virtual memory area and cannot access other memory locations unless explicitly authorized.
This kind of division allows the kernel to be isolated from the rest of user applications and to prevent malicious code to read the memory used by other processes(at least without a privilege escalation).
In order to communicate to kernel mode from user space, the GNU C library(glibc) uses some particular interfaces exposed by the kernel called system calls. We will discuss this topic in the part three of this guide, for now let us just assume that a syscall is a sort of API to communicate with the kernel.
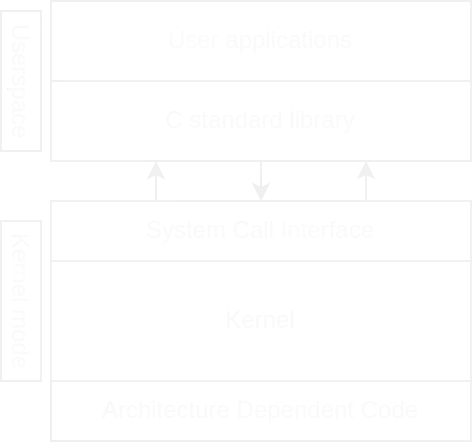
The Linux kernel running in supervisor mode, can be divided in three different sections:
- System call interface;
- Kernel code(architecture independent code);
- Architecture dependent code;
System Call Interface(SCI)
THe System Call Interface implements basic functionalities such as
read,
write, open or exit.
These functions are used by the C standard library to provide high level functions
such as fopen, malloc or
pthread_create.
The Linux SCI is guaranteed to be POSIX compliant.
Kernel Code
The kernel code(also known as platform independent code) is a portion of the kernel containing code common to all architecture supported by Linux. This layer includes the process scheduler, the device drivers, the virtual file system, the network stack and the memory management subsystem.
Architecture Dependent Code
This last layer contains the code needed to make the Linux work on a specific architecture. This part of Linux includes the Board Support Package(BSP), which provides basic functionalities used to initialize the processor. The BSP also include the bootloader. Some main tasks of the BSP are:
- Enter either protected or long mode;
- Initialize the clock hardware(for instance, in IBM PC hardware this is called PIT);
- Configure random access memory.
Kernel Code functionalities
The second layer of the previous diagram, can be further divided into subsection according to the functionalities provided by Linux.
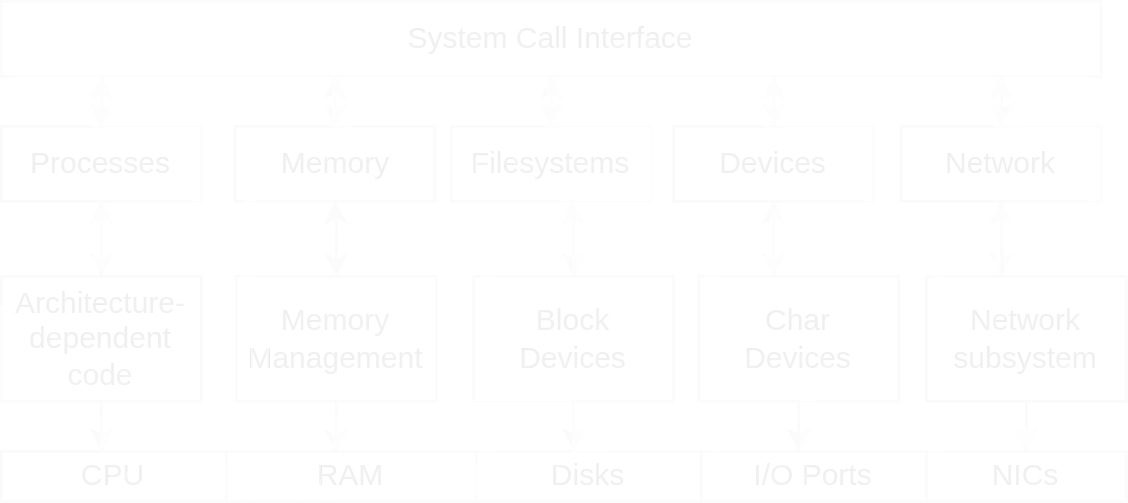
- Process Management: this part of the kernel is in charge of executing processes. The code that assign a resource to a certain task is called the scheduler.;
- Memory Management: this part of the kernel deals with memory pages. It also provides other memory mechanism such as file swapping;
- File Systems: this layer provides an abstract implementation of a file system(VFS) on top of more concrete file systems(such as ext4, xfs, etc.);
- Devices: the biggest part of the kernel. This includes drivers that make devices(such as keyboards, webcams, audio cards, etc.) usable;
- Network: implementation of the network stack according to the supported protocols(such as TCP/IP).
Kernel Hello World
Now that we have a basic understanding of the architecture of the Linux kernel, we can start to write our first kernel module. Our first example will be a simple hello world module that will just print a message when loaded. Since Linux is modular, there is no need to recompile the whole kernel from scratch, we can load our module at runtime without even rebooting the virtual machine.
First, we need to install the Linux headers, if you are using Arch Linux with the lts kernel, type the following:
[marco@archlinux hello_world]$ sudo pacman -S linux-lts-headers
then create a new working directory called
helloworld with two files called
Makefile and
hello.c.
[marco@archlinux hello_world]$ tree
.
|-- Makefile
`-- hello.c
0 directories, 2 files
The Makefile template will look like this:
obj-m += hello.o
CFLAGS = -Wall -Wextra -Werror -std=c99
all:
make -C /lib/modules/$(shell uname -r)/build/ M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build/ M=$(PWD) clean
Let us now start writing the Linux module. The first thing we need to do is to import the required headers:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
The first one is mandatory for any module,
kernel.h is needed for
KERN_* log levels and
init.h
is needed for
__init and
__exit functions. Then, we need to provide some
information about our module, for instance we could state the license(GPL, BSD, MIT or dual),
the author(s), the version and a brief description of the code.
To do that, we can use the following functions:
MODULE_LICENSE("Dual BSD/GPL");
MODULE_AUTHOR("Marco Cetica");
MODULE_VERSION("0.1");
MODULE_DESCRIPTION("Hello World");
Now we are ready to define the core of our module. Unlike any other C program, Linux kernel modules do not have a main function, instead they require us to define two separate methods that control the behavior of the module at loading and unloading time. The name of these methods is arbitrary, in my example, I’ve named them startup and shutdown:
static int __init startup(void) {
printk(KERN_INFO "Hello World from the kernel!\n");
return 0;
}
static void __exit shutdown(void) {
printk(KERN_WARNING "So long...\n");
}
Inside both functions, we just print a message. Do note that we cannot
use standard C functions like
printf or
puts since we are in kernel mode.
Instead, we can use the
printk function. This method allow us to
specify the importance of the message we are trying to send(just
like a logging function).
In this example, I’ve used
KERN_INFO and
KERN_WARNING but there are many other logging levels available:
| Name | Description |
|---|---|
| KERN_EMERG | An emergency condition, system may be unresponsive |
| KERN_ALERT | A problem that requires immediate attention |
| KERN_CRIT | A critical condition |
| KERN_ERR | An generic error |
| KERN_WARNING | A warning |
| KERN_NOTICE | A normal message that may require attention |
| KERN_INFO | An informational message |
| KERN_DEBUG | A debug message |
It is worth noticing that the init function must return 0, any other return code suggests that the module has not been loaded correctly. Finally, we register the functions name as the init and exit functions, respectively:
module_init(startup);
module_exit(shutdown);
Below the complete source code:
/*
* Linux Kernel Module - hello world example
* Dec. 2021
*/
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
// Specify Author, License, Version and Description
MODULE_LICENSE("Dual BSD/GPL");
MODULE_AUTHOR("Marco Cetica");
MODULE_VERSION("0.1");
MODULE_DESCRIPTION("Hello World");
// This function is called when the module
// is loaded into the kernel
static int __init startup(void) {
printk(KERN_INFO "Hello World from the kernel!\n");
return 0;
}
// This function is called when the module
// is unloaded from the kernel
static void __exit shutdown(void) {
printk(KERN_WARNING "So long...\n");
}
// Register the init and exit functions
module_init(startup);
module_exit(shutdown);
Let us now try it. After compiling the module with
make,
you will find some new files in your working directory.
[marco@archlinux hello_world]$ tree
.
|-- Makefile
|-- Module.symvers
|-- hello.c
|-- hello.ko
|-- hello.mod
|-- hello.mod.c
|-- hello.mod.o
|-- hello.o
`-- modules.order
0 directories, 9 files
To load the module, type:
[marco@archlinux hello_world]$ sudo insmod hello.ko
To see if the module has been loaded, you can either use lsmod
[marco@archlinux hello_world]$ lsmod | grep hello
hello 16384 0
or dmesg:
[marco@archlinux hello_world]$ sudo dmesg -W
[ 3482.649180] Hello World from the kernel!
[ 3536.916351] So long...
To unload the module you can use sudo rmmod hello.
That’s it, you wrote your first Linux kernel module! In the next part of this guide we will try to build a module that will hash a string from userspace. This will allow us to explore more advanced Linux topics such as char/block devices and internal Linux APIs.